

中 알리바바 AI가 Claude 턱밑까지 왔다는데, 믿어도 될까?
알리바바의 AI 연구팀 Qwen이 4월 1일 새로운 대규모 언어 모델 'Qwen3.6-Plus'를 공개했습니다. 지난 2월 내놓은 Qwen3.5 시리즈의 후속 모델로, 알리바바 클라우드 모델 스튜디오 API를 통해 바로 사용 가능한데요. 한 번에 처리할 수 있는 텍스트 양,

알리바바의 AI 연구팀 Qwen이 4월 1일 새로운 대규모 언어 모델 ‘Qwen3.6-Plus’를 공개했습니다.
지난 2월 내놓은 Qwen3.5 시리즈의 후속 모델로,
알리바바 클라우드 모델 스튜디오 API를 통해 바로 사용 가능한데요.
한 번에 처리할 수 있는 텍스트 양,
즉 문맥 창(Context Window)은 기본 100만 토큰에 달했습니다.
책 한 권 분량의 텍스트를 한꺼번에 읽고 이해할 수 있는 수준이었습니다.
공식 기술 블로그를 통해 Qwen 개발팀은
“ 전작 출시 이후 사용자들에게 받은 피드백을 이번 모델에 직접 반영했다 “
라고 밝혔습니다.
그 결과 이번 신규 모델은 코딩 에이전트 성능과 여러 종류의 정보를 동시에 처리하는 멀티 모달 추론 능력이 눈에 띄게 좋아졌습니다. 간단한 웹 페이지를 만드는 수준을 넘어,
대규모 코드 저장소 전체를 다루는 복잡한 문제도 풀어낼 수 있고,
이미지·영상·문서를 함께 분석하는 작업도 해낼 수 있게 되었습니다.
Qwen 측이 공개한 기술 문서를 바탕으로 주요 내용을 아래와 같이 정리했습니다.
코딩 에이전트 성능, Claude Opus 4.5와 대등한 수준 진입
문서 이해·공간 지각·영상 분석…멀티 모달 7개 부문 1위
OpenAI · Anthropic API 규격 동시 지원…모델 전환 ‘원클릭’
그럼 이 내용을 중심으로 오늘 글을 시작하겠습니다.
1. 코딩 에이전트 성능, Claude Opus 4.5와 대등한 수준 진입
이번 모델에서 가장 크게 발전한 분야는 “코딩 에이전트”였습니다.
코딩 에이전트란 사람이 “이 버그를 고쳐줘”처럼 지시만 내리면,
AI가 알아서 코드를 분석하고 수정 계획을 세운 뒤 직접 고치는 기술을 말합니다.
벤치마크 점수를 보면 세계 최고 수준 모델들과 거의 대등한 것으로 나타났습니다.
‘SWE-bench Verified’에서 78.8점을 받아 Claude Opus 4.5(80.9점)를 바짝 뒤쫓았고,
고난도 문제만 모은 ‘SWE-bench Pro’에서는 56.6 대 57.1로 사실상 대등했습니다.
다국어 코딩, 터미널 명령어, 웹 화면 생성 등 나머지 세부 벤치마크에서도 최상위권을 유지했습니다.
일부 항목에서는 아예 경쟁 모델을 넘어서기도 했습니다.
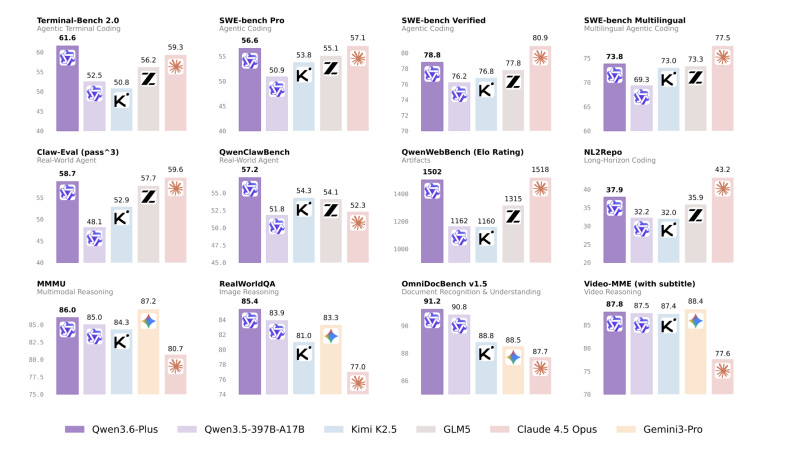
복잡한 터미널 명령어를 얼마나 잘 다루는지 보는
‘Terminal-Bench 2.0’에서 61.6점을 받아
Claude Opus 4.5(59.3점)를 제쳤고,
웹 화면을 만드는 능력을 측정하는 ‘QwenWebBench’에서도 1501.7점으로 최상위권을 기록했습니다.
Qwen 개발팀은 단순히 점수가 높은 것보다 중요한 건, 논리적 추론·맥락 기억·도구 활용 능력이 하나로 어우러진 ‘올라운더’ 역량”이라고 강조했습니다.
코딩뿐 아니라 범용 에이전트 영역에서도 성과가 뚜렷했습니다.
복잡한 계획을 짜야 하는 ‘TAU3-Bench’에서 70.7점으로 Claude Opus 4.5(70.2점)를 앞질렀고,
‘DeepPlanning’에서는 41.5점으로 비교 대상 모델 가운데 가장 높은 점수를 기록했습니다.
외부 도구를 정확하게 호출하는 능력을 보는 ‘MCPMark’에서도 48.2점으로 1위를 차지했습니다.
수학·과학 추론도 최상위권이었습니다.
대학원 수준 과학 문제(GPQA)에서 90.4점으로 1위를 차지했고,
수학 경시대회급 난이도의 AIME26· HMMT에서도 95점 이상을 기록했습니다.
사용자의 지시를 얼마나 정확히 따르는지를 보는 ‘IFEval’에서는 94.3점으로, Claude Opus 4.5(90.9점)를 누르고 전체 1위를 달성했습니다.
다국어 처리 능력도 우수했습니다.
29개 언어 평균 성능을 측정하는 ‘MMLU-ProX’에서 84.7점,
번역 품질 평가인 ‘WMT24++’에서 84.3점을 받았습니다.
다만 이번 벤치마크 수치는 Qwen 측이 자체 공개한 결과이며, 독립적인 제3자 검증은 아직 이루어지지 않았습니다.
또한 벤치마크 점수와 실제 현장 성능 사이에는 늘 간극이 존재하는 만큼, 실사용 평가가 뒤따라야 할 것입니다.
코드를 읽고 고치는 능력이 사람에 가까워졌다면, 다음 질문은 자연스럽습니다.
“코드 말고 이미지, 영상, 문서도 그만큼 잘 다룰 수 있을까?”
Qwen3.6-Plus는 이 질문에도 점수로 답했습니다.
<이어지는 내용은 아래와 같습니다>
GPT5.2와 Gemini-3 Pro를 넘어선 멀티 모달 7개 부문의 세부 점수를 뜯어봅니다.
Claude나 ChatGPT를 쓰던 개발자가 설정 몇 줄만 바꿔 갈아탈 수 있다는데,
정말 그런지 따져봅니다.
마지막으로 Qwen 팀이 직접 제시한
3D 게임, 자동 프레젠테이션, 쇼핑 에이전트의 사례를 소개합니다.